Show me the data (part 3)
 Image credit: https://hackersbyrez0.com/
Image credit: https://hackersbyrez0.com/
We have reviewed several classes of data, but one of the most important—and challenging—types remains: network traffic data. Its significance stems from the fact that many attacks originate from network-based vectors. However, analyzing network data presents several challenges. First, network traffic generates massive volumes of data, much of which may have limited analytical value. Second, effective processing is crucial to identify meaningful patterns and potential threats within this data. Finally, network data’s complex structure poses unique difficulties: packet captures and network flows require specialized libraries and often custom code to transform them into structured formats suitable for machine learning models.
I have the opportunity here to share my personal experience, as I work with this type of data daily. You can find the code from this blog in the accompanying notebook blog_show_data_3.ipynb.
1,000 ft view
Our big picture roadmap is listed below:
- Cybersecurity Data
- Logs/Events (part 1)
- syslog
- server log
- host event logs
- Pandas (part 2)
- Unstructured text
- domains
- urls
- Binaries
- Traces (we are here)
- pcaps
- netflow
Traces
Network traces are collected as packet captures, or PCAP files, which contain a wealth of information but cannot be parsed with simple text-processing functions. The primary tool for visualizing PCAPs is Wireshark. In a previous example, I used a packet capture that I had exported to a CSV file. You can do this using Wireshark through the ‘Export Packet Dissections’ option. Note that exporting to CSV includes only the visible data columns in Wireshark, which can lead to some data loss.
For more comprehensive parsing of packet captures, scapy is a great tool. Recently, I’ve also started using pyshark, a Python wrapper for tshark. Each library has its strengths and weaknesses, and I’ve encountered challenges like packet layer loss, parsing inconsistencies, and cross-platform version differences. Despite these issues, both libraries are robust enough to save you from having to build custom PCAP parsing solutions from scratch.
Let’s start with reading a packet capture using rdpcap from scapy:
from scapy.all import rdpcap
pcap = rdpcap("../data/blog3/2023-01-23-Google-ad-to-possible-TA505-activity.pcap")
In this example, we read a pcap and store it in a special scapy object, the PacketList. From there, the sky is the limit on what you can do since scapy can manipulate the whole OSI stack for your parsing.
from scapy.layers.inet import IP, UDP
dns_count = 0
for packet in pcap:
try:
# extract IP layer for UDP protocol
udp = packet[IP][UDP]
# pick your favorite UDP service... it's always DNS
if udp.dport == 53:
print(packet)
dns_count += 1
except:
continue
dns_count
You can count DNS requests or any other protocol requests, create graphs, etc.
Attack payloads
Another cool thing that you can do after you parse your packet capture is analyze payloads, such as HTTP, that you may suspect are malicious.
Below is an example that finds the payload in each packet, checks if it is HTTP, and then parses the method, path, and protocol, as well as headers if they exist. The result is a structured dictionary for each HTTP packet payload.
To extract all HTTP packets, we use the function get_http:
def get_http(packet: scapy.layers.l2.Ether) -> dict:
"""Gets all http fields and the body of the request if it exists.
Args:
packet (scapy.layers.l2.Ether): List of packets read from pcap.
Returns:
dict: Dictionary of the form: {"http_fields": http_fields, "body": body}, where http_fields is a list of http request rows and body is a string with the body of the request.
"""
http_fields = []
body = None
if packet.haslayer(TCP) and packet.haslayer(Raw):
try:
# this generates UnicodeDecodeError if the Raw layer is not formatted properly
payload = str(packet[Raw].load, "utf-8")
if "HTTP/" in payload:
if "\r\n\r\n" in payload:
body = payload.split("\r\n\r\n")[1]
else:
body = payload.split("<!DOCTYPE html>")[1]
# split each row of each http request, make a list of strings with these rows
http_fields = payload.split("\r\n")
except:
return
return {"http_fields": http_fields, "body": body}
Note that the if statement if packet.haslayer(TCP) and packet.haslayer(Raw): filters the HTTP requests by checking for both the TCP and application layers (Raw). We then extract the payload as a string from the packet with payload = str(packet[Raw].load, "utf-8"). This step can be tricky, as encoding issues may cause errors.
Next, we rely on the structure of an HTTP request, specifically recognizing that \r\n\r\n is a common delimiter in HTTP messages. This sequence marks the end of the header section and the beginning of the body, where \r\n represents a carriage return (\r) followed by a newline (\n), which is the standard line-ending sequence in HTTP headers. After splitting the payload by this sequence, the first line of the request, located at index [0], contains the start of the HTTP header, while the second element at index [1] holds the message body. Below is an example of what the HTTP request may look like (modified from our pcap):
GET /download/AnyDeskSetup_26b30163.msi HTTP/1.1\r\n
Host: anydeskcloud.tech\r\n
Connection: keep-alive\r\n
Accept-Encoding: gzip, deflate\r\n
Accept-Language: en\r\n
\r\n
<!DOCTYPE html>
</html>
In this modified example, the HTTP body is:
<!DOCTYPE html>
</html>
The rows above the HTTP body form the list of lines in http_fields. These two elements are what our function returns: a set of lines from which we can extract HTTP fields and the body of the request, both organized in a dictionary structure return {"http_fields": http_fields, "body": body}.
Now we are ready to parse these HTTP fields into another neatly structured dictionary using the following function:
def parse_http_request(http_request: dict) -> dict:
"""Parses HTTP request fields to a dictionary.
Args:
http_request (dict): a list of http request rows.
body (str):tring with the body of the request.
Returns:
dict: HTTP request fields dictionary.
"""
try:
# this generates a ValueError if the http request does not have the proper structure
method, path, protocol = http_request["http_fields"][0].split(" ")
headers = {}
for header in http_request[1:]:
if header:
header_name, header_value = header.split(":", maxsplit=1)
headers[header_name] = header_value.strip()
parsed_path = urllib.parse.urlparse(path)
return {
"timestamp": str(packet.time),
"source_ip": packet[IP].src,
"dest_ip": packet[IP].dst,
"source_port": packet[TCP].sport,
"dest_port": packet[TCP].dport,
"method": method,
"path": parsed_path.path,
"query_string": parsed_path.query,
"protocol": protocol,
"headers": headers,
"body": http_request.get("body"),
}
except:
# http header may be non-standard, may have no method or may be error code like 302
return {
"timestamp": str(packet.time),
"source_ip": packet[IP].src,
"dest_ip": packet[IP].dst,
"source_port": packet[TCP].sport,
"dest_port": packet[TCP].dport,
"body": http_request.get("body"),
}
We start by examining the first row in the http_fields list: method, path, protocol = http_request["http_fields"][0].split(" "). This line extracts important information such as the HTTP method, path, and protocol. Next, we retrieve all header fields, which, as shown, are separated from their values by :. For instance, the Host field in an HTTP request appears as Host: anydeskcloud.tech. If the request does not follow the standard format, the code will handle this scenario by branching to the except block.
Finally, we put everything together and run the code with the pcap example:
for packet in pcap:
http_request = get_http(packet)
if http_request and http_request.get("http_fields"):
parsed_payload = parse_http_request(http_request)
if parsed_payload != None:
pprint.pprint(parsed_payload)
We use pprint to do a pretty printout of the data.
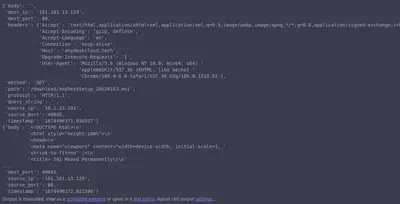
I hope you now have a sense of how complex it is to parse these traces. Even with sophisticated libraries like scapy, we still need to put in considerable effort to extract all the meaningful fields for our models and organize them into a structured format, such as a dictionary. This structure is essential for applications like classification, prediction, and other powerful uses in machine learning.
Netflow
NetFlow is a Cisco protocol for network telemetry that provides statistics based on flows. A flow is defined as a unidirectional sequence of packets between a source and destination, identified by the tuple (source IP, source port, destination IP, destination port, protocol). One tool for collecting and processing network data is nfdump, which we will use to post-process router data.
First install nfdump and convert the nfcapd binary to a readable csv file:
# install nfdump
sudo apt-get install nfdump
# convert nfpcapd file to csv
nfdump -r ./data/blog_show_data/nfcapd.202304172010 -o csv > netflow_data.csv
Now it is business as usual. Let’s convert the csv to a Pandas DataFrame, and then we can put the data in a dictionary and print it. The sky is the limit:
import pandas as pd
# Path to the converted NetFlow CSV file
csv_file = "../data/blog_show_data/netflow_data.csv"
# Read the CSV file into a DataFrame
df = pd.read_csv(csv_file)
# Set display options to show all columns
pd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
# Display the DataFrame
df.head()

Recap
We’ve covered the foundational methods for parsing cybersecurity data, the first stage in ML projects. In the upcoming posts, we will dive into the next step: exploratory data analysis, where we treat the data as a black box with an intriguing story to uncover. Stay tuned
– Xenia
Going Even Deeper
Code examples for this blog can be found in cyber-ml repo.
Pcap
- Datasets
- Python libraries for pcaps
Netflow