Exploring the data - AI
 Image credit: https://hackersbyrez0.com/
Image credit: https://hackersbyrez0.com/
Exploratory Data Analysis (EDA) is an essential process for understanding your data, but it can often feel overwhelming. Summarizing datasets typically involves intricate mathematics, and generating meaningful visualizations requires extensive coding. To simplify this process, I am excited to discuss the Pandas AI package, which enables you to perform EDA by asking questions in natural language. Automation plays a key role in reducing repetitive tasks and avoiding redundant efforts, and in this blog, we will explore Python libraries that streamline EDA.
We’ll start by experimenting with Python libraries that integrate statistics and visualization to automate EDA. Following this, we’ll dive into how Pandas has evolved with AI capabilities to make data exploration even more intuitive. You can find all the code used in this blog in the notebook blog_eda_3.ipynb.
1,000 ft view
What?
Pandas AI is an open-source package that integrates language models like GPT-3.5 and GPT-4.0 with Pandas’ DataFrame abstractions. This synergy enables you to interact with your data using natural language. With Pandas AI, you can ask questions, test hypotheses, extract features, and even generate graphs—all through intuitive commands. The package supports both generic functions and custom prompts for tailored exploration.
Why?
Time and resource constraints often demand simple and efficient solutions for Exploratory Data Analysis (EDA). Pandas AI addresses this need by enabling quick statistical calculations and data summarization with just a few lines of code, eliminating the complexity of manual math. When combined with tools like skimpy, summarytools, and sweetviz for summaries and visualizations, you can complete your EDA in under 20 lines of code.
How?
Let’s recap the three parts of EDA that we are currently exploring. We are at the last part, putting everything together with AI powered EDA.
- Exploratory Data Analysis
- Graphical techniques (part 1)
- Histograms
- Scatter
- Box
- Autocorrelation
- Statistical techniques (part 2)
- Location
- Scale
- Skewness
- Randomness
- Distribution measures
- Outliers
- Automation (part 3 - we are here)
- EDA Python libraries
- Pandas AI
Load data
We will use a pretty neat trick to load the data that we generated in the previous blog posts. Remember that these data was saved in pkl (read “pickle”), a serialized Python object, using the Pandas function to_pickle:
mirai_df.to_pickle("../data/blog_eda/mirai.pkl")
benign_df.to_pickle("../data/blog_eda/benign.pkl")
Remember, mirai_df and benign_df contain the packet captures from Mirai botnet traffic and regular network traffic, respectively. In the previous blog, we read, processed, and transformed these packet captures into Pandas DataFrames, converting all values to numerical formats. Now, we can easily load this processed data from a pkl file.
mirai_df = pd.read_pickle("../data/blog_eda/mirai.pkl")
benign_df = pd.read_pickle("../data/blog_eda/benign.pkl")
We often use this technique in our blogs to save time and seamlessly transfer processed data between notebooks. Here, we’ll load the pkl files containing the processed network flows, which have been transformed into numeric data or features. If you’d like a refresher on how these pickle files were created, take a look at the EDA Part 1 and EDA Part 2 blogs.
mirai_flow_df_numeric = pd.read_pickle("../data/blog_eda/mirai_flow_numeric.pkl")
benign_flow_df_numeric = pd.read_pickle("../data/blog_eda/benign_flow_numeric.pkl")
EDA Python Libraries
To wrap up our discussion on EDA, I’d like to highlight three of my favorite libraries for statistics and visualizations: sweetviz, summarytools, and skimpy. While these tools are incredibly useful, there are a couple of important considerations:
-
Rendering Limitations: Both
summarytoolsandskimpyrender exclusively in Jupyter notebooks. Despite this constraint, they offer rich insights with minimal effort, providing quick overviews of summary statistics, distributions, missing values, duplicates, and more. -
Input Requirements: All these libraries require numeric data as input to function properly and avoid errors. This means we will need to convert non-numeric data, such as IP addresses, into numeric formats. Thankfully, Python offers plenty of libraries to simplify such transformations.
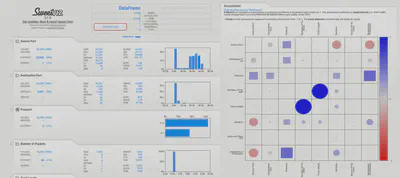
sweetviz
As the name implies, this is a pretty sweet set of visualizations that you can share with anyone in your team because they render your data to HTML. Here are the three lines of code to generate these:
import sweetviz as sv
my_report = sv.analyze(mirai_flow_df_numeric)
my_report.show_html()
The figure below shows part of the visualization (due to space limitations):
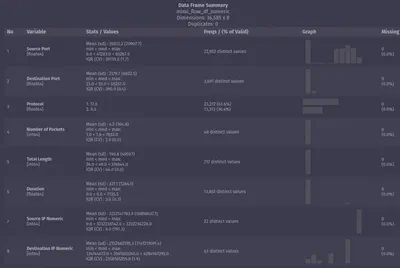
summarytools
To depict data distributions and calculate useful statistics, you can use the package summarytools:
from summarytools import dfSummary
dfSummary(mirai_flow_df_numeric)
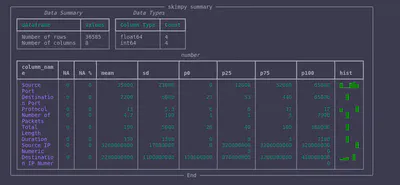
skimpy
Last but not least, skimpy offers another view of summary statistics, percentiles, and histograms:
from skimpy import skim
skim(mirai_flow_df_numeric)
I refer to these packages as “automation tools” for EDA because they provide a wealth of visualizations and statistics with minimal coding effort. They have been helpful for gaining an initial understanding of my data, and I hope you will find them just as valuable.
Pandas AI
The advancements in Large Language Models (LLMs) have paved the way for exciting new applications. One such innovation is the integration of LLMs with Pandas DataFrames, which opens up powerful new possibilities for data analysis.
To use Pandas AI, you will need an LLM API key. I am using OpenAI. To get started, you need to create an OpenAI API key. Save the API key in a .env file and ensure this file is included in your .gitignore to protect your secrets from being exposed in version control systems. Then, securely load the key into your project using the python-dotenv package:
from dotenv import load_dotenv
# finds .env file and loads the vars
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY", "Key not found")
You will need to include in your .env file is the following line:
OPENAI_API_KEY=<your key>
Interact with your data
Now that everything is set up, we’re ready to ask questions about our data. To get started, we will create an LLM object to interface with the OpenAI API. Next, we will use this LLM object to initialize a PandasAI instance, enabling us to interact with our data effortlessly.
# pandasai imports
from pandasai.llm.openai import OpenAI
from pandasai import PandasAI
# Instantiate a LLM
llm = OpenAI(api_token=openai_api_key)
pandas_ai = PandasAI(llm)
The easiest thing to do is to use an out of the box function to clean our data from duplicate and None values:
from pandasai import SmartDataframe
mirai_smart = SmartDataframe(df=pd.DataFrame(mirai_df), config={"llm": llm})
mirai_cleaned_df = mirai_smart.clean_data()
benign_smart = SmartDataframe(df=pd.DataFrame(benign_df), config={"llm": llm})
benign_cleaned_df = benign_smart.clean_data()
The SmartDataframe object transforms Pandas DataFrames into formats that the LLM can understand. For instance, a simple function like clean_data() leverages LLM-powered prompts to remove duplicates and None values automatically. If you check the shape of your DataFrame before and after running clean_data(), you’ll notice a reduction in rows due to the cleanup.
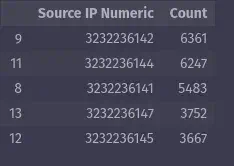
Now, let’s identify the most frequently used source IPs in the Mirai PCAP dataset:
top_5_source_IPs = pandas_ai(
mirai_clean_df, prompt="Which are the 5 most popular source IP addresses?"
)
top_5_source_IPs
Next, let’s find the most popular services that Mirai botnet was targeting:
top_5_dst_ports = pandas_ai(
mirai_clean_df, prompt="Which are the 5 most popular destination ports?"
)
top_5_dst_ports
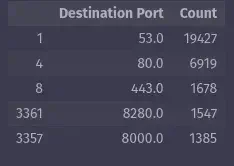
This approach relies on actual LLM-driven prompting rather than pre-defined functions, allowing for a more flexible and intuitive way to explore your data. Imagine all the questions you can ask without the need for complex math or crafting regular expressions.
Generate Graphs
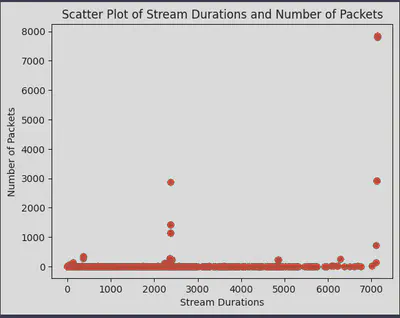
Pandas AI also makes it easy to create basic plots through simple prompts:
pandas_ai.run(
mirai_clean_df,
prompt="Plot the scatter plot of stream durations and number of packets.",
)
pandas_ai.run(benign_clean_df, prompt="Plot a barplot of top 10 destination ports.")
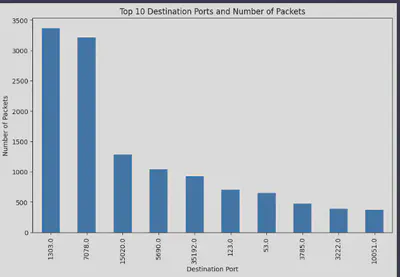
In this example, we skipped the need to read lengthy documentation on plotting and still produced meaningful results. Although these plots may not offer the same level of customization as those created with traditional coding methods, they effectively deliver a clear and concise visual representation of our data.
The cybersecurity perspective
As we conclude our exploration of EDA with automation and AI, it is essential to reflect on its implications from a cybersecurity standpoint:
- Automation with Python Libraries: While these tools are excellent for saving time and gaining insights, they may face challenges when handling cybersecurity data, which often includes non-numerical features. This limitation can result in logical or runtime errors.
- Python Libraries and LLMs: Treating these tools as black boxes is not ideal for critical applications or cybersecurity data. While they are valuable for exploratory tasks, building detection models or making predictions about network traffic demands a thorough understanding of the data and the underlying processing methods.
- Pandas AI and Zero Trust: The use of Pandas AI conflicts with the “zero trust” principle, as it relies on LLMs to generate and execute code on Pandas DataFrames without prior review. To mitigate potential risks, it’s recommended to use a sandboxed environment for running Pandas AI code, ensuring an additional layer of security.
- Pandas AI and privacy: A common concern with LLMs is the potential exposure of Personally Identifiable Information (PII) when data is sent to an open model, which might use it for training purposes. To address this, consider deploying models locally or on trusted servers to ensure data privacy and security.
Recap
We explored the powerful PandasAI package, a tool that simplifies gaining insights from data. As language models continue to evolve and the open-source Pandas AI community expands its contributions, I’m excited about the potential this tool holds for empowering cybersecurity analysts.
That said, it’s important to approach results with caution. Since this framework relies on a language model as a black box, it’s always a good idea to validate some of its outputs using traditional Python functions.
Imagine the possibilities of training a custom language model specifically designed for cybersecurity data analytics, offering greater transparency and control. While such an endeavor requires significant time, resources, and exploration beyond the scope of this blog, it represents an exciting frontier.
In future posts, we’ll dive deeper into how Pandas AI can assist with feature engineering and explore the capabilities of LLMs for modeling with scikit-llm. Stay tuned!
– Xenia
Going Even Deeper
- Pandas AI examples
- Prompt Engineering Guide: this can help you generate elaborate prompts for your Pandas AI
- Everything I will forget about prompt engineering
Code examples for this blog can be found in the notebook blog_eda_3.ipynb.